
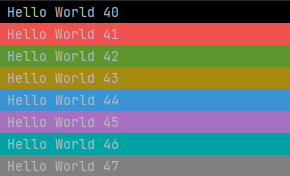
Java在控制台上的输出字体样式其实是可以自己定义的代码如果结尾处没有加 \033[m 这次输出后的全部输出都会变成相同样式 System.out.println("\033[30m"+"Hello Wor...
阅读全文...
移动硬盘安装Linux系统闪屏问题解决方案
前引电脑自带的固态只有120GB,着实有点嫌小就换了个大一点的,原来的就被我做成了移动硬盘。但是已经有很多可以使用的U盘,对速度也没有太高的追求,与其被丢在角落里吃灰,不如在移动盘里烧录个Linux,和原本主机的Windows一起做双系统使用,做个即插即...
阅读全文...
阅读全文...

利用GitHub Action自动集成部署Hexo博客到服务器
前引Hexo生成的静态博客有着安全、快速等特点,但是同时也存在一些比较明显的痛点由于没有后台,出现错误时移动端修改不方便本地文件丢失,很难找回原本博客配置文件没有Nodejs环境不能部署而这些问题都能通过Github Action得到比较好的解决Hexo...
阅读全文...
阅读全文...

Hexo搜索引擎优化(SEO)
前引我们费尽心血写出来的各种博客,当然是希望分享给更多的人,让更多的人看到的,但是如果只是在自己的小圈子里面去分享的话,很难有好的浏览量,所以就需要我们去优化搜索,让浏览器收录我们的网址,这样在有人在浏览器搜索对应关键字的时候就有可能将我们的文章推荐给他...
阅读全文...
阅读全文...

MySql入门基础命令
{% note info simple %}该文章为个人学习笔记,内容仅供参考{% endnote %}主要参考以下两个网站{% flink %}class_name: 参考网站class_desc:link_list:name: MySQL 5.1中文...
阅读全文...
阅读全文...

接入每天60S看世界API
Timeline{% timeline 更新日志 %}文章发布将XMLHttpRequest替换为fetch,增加打字机效果{% endtimeline %}前言目前在网上已经有很多博主出了对博客引入这个API的教程,内容也已经比较详细,但是很多通过直接...
阅读全文...
阅读全文...


Windows安装ESP-IDF官方工具
官方文档ESP官方 在Windows上的安装流程已经非常完善了,但是ESP-IDF 工具安装器在国内由于一些众所周知的原因下载速度会比较慢下载ESP-IDF工具安装器ESP-IDF工具安装器 最好选择离线安装器,在线安装器安装的速度是真心慢(能科学上网的...
阅读全文...
阅读全文...


搭建一个个人的专属图床
什么是图床图床就是用来存放图片的空间,同时允许外链到其他网站。按照我自己的话来说,图床就是给自己的图片挂上一个链接,其他人能通过这个链接看到这张图片的一个服务器。为什么要搭建图床网站图片像我网站的背景图片、Logo、文章封面等等都是通过图床的链接实现的,...
阅读全文...
阅读全文...
最新文章










最新评论

管理控制台本身占用不大,我在一台2核2G的服务器上搭建,四五个人...
Mango / 2025-07-3 6:51

请问这个管理控制台占用怎样,因为云服务器配置不高,然后这个可以开...
shang / 2025-07-1 3:39
博客样式和功能已经做了比较多的完善,有很多参考了别人的创意,参考...
Mango / 2024-07-24 13:54
二叉树的遍历看这个图真的特清晰 ::aru:shy2::
Mango / 2024-07-18 10:30
怎么会有人蠢到上传代码没有提交审核,睡前才想起来 ::aru:c...
Mango / 2024-05-12 18:18
很多事情坚持很重要,不需要做的有多好,但是一定要坚持去做。愿你的...
Mango / 2024-05-11 16:37